

Read Time:1 Minute, 52 Second
Remember the cable, phone and internet combo offers that used to land in our mailboxes? These offers were highly optimized for conversion, and the type of offer and the monthly price could vary significantly between two neighboring houses or even between condos in the same building.
I know this because I used to be a data engineer and built extract-transform-load (ETL) data pipelines for this type of offer optimization. Part of my job involved unpacking encrypted data feeds, removing rows or columns that had missing data, and mapping the fields to our internal data models. Our statistics team then used the clean, updated data to model the best offer for each household.
That was almost a decade ago. If you take that process and run it on steroids for 100x larger datasets today, you’ll get to the scale that midsized and large organizations are dealing with today.
Each step of the data analysis process is ripe for disruption.
For example, a single video conferencing call can generate logs that require hundreds of storage tables. Cloud has fundamentally changed the way business is done because of the unlimited storage and scalable compute resources you can get at an affordable price.
To put it simply, this is the difference between old and modern stacks:
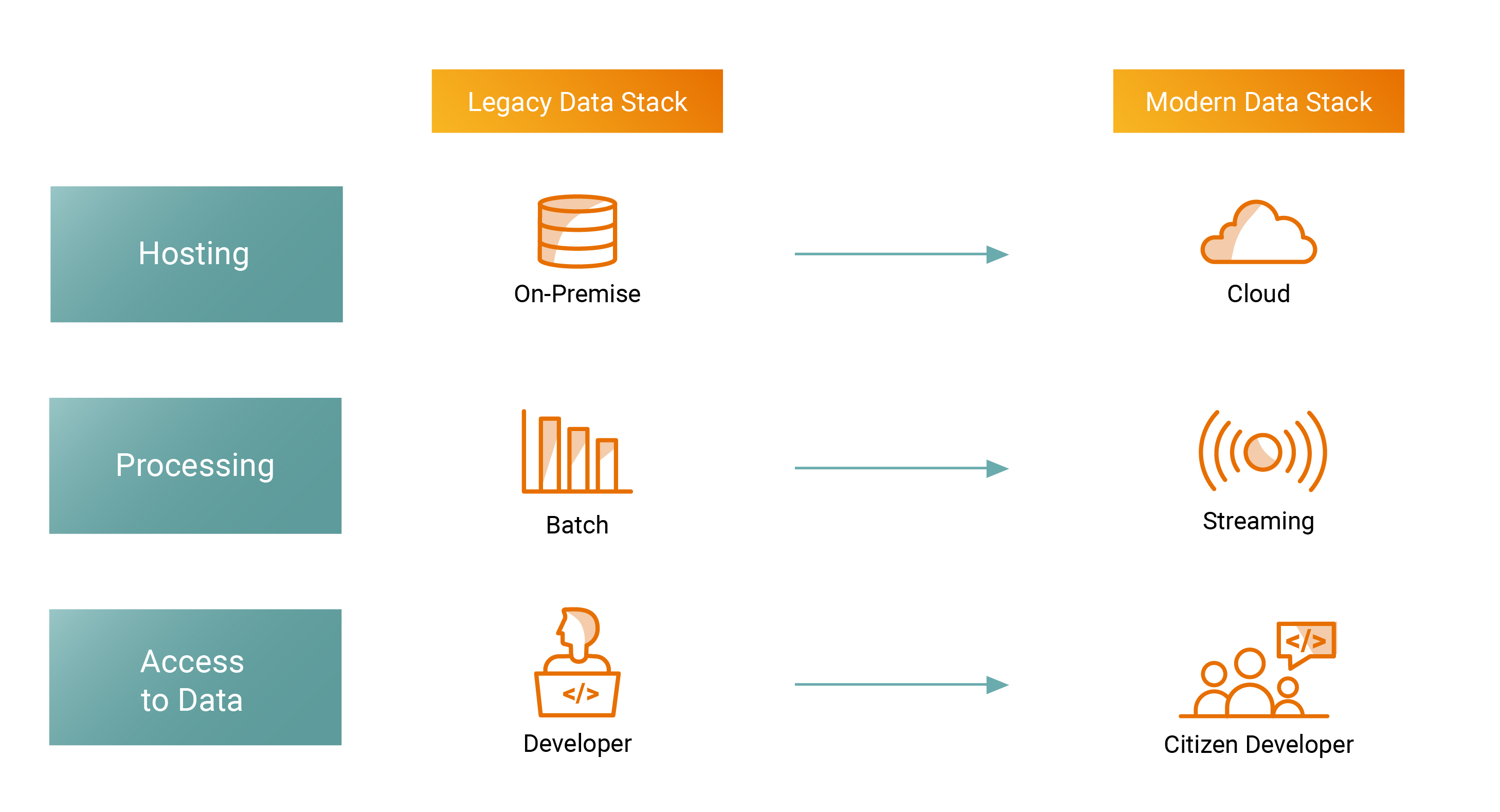
Image Credits: Ashish Kakran, Thomvest Ventures
Why do data leaders today care about the modern data stack?
Self-service analytics
Citizen-developers want access to critical business dashboards in real time. They want automatically updating dashboards built on top of their operational and customer data.
For example, the product team can use real-time product usage and customer renewal data for decision-making. Cloud makes data truly accessible to everyone, but there is a need for self-service analytics compared to legacy, static, on-demand reports and dashboards.
Is the modern data stack just old wine in a new bottle? by Ram Iyer originally published on TechCrunch

Happy
0 %
Sad
0 %
Excited
0 %
Sleepy
0 %
Angry
0 %
Surprise
0 %

